K2E-B-G5-8 · Paper Note
vMAP
- Description:vMAP 论文笔记 — 对象级神经隐式建图,每物体一个小 MLP,向量化批量并行训练几十个 MLP 实时建图,可拆/可重组场景
- My Notion Note ID:K2E-B-G5-8
- Created:2024-03-31
- Updated:2026-06-11
- License:转载欢迎:转载请注明作者 Yu Zhang 并附原文出处(yuzhang.io)
Table of Contents
- 1. Summary
- 2. Key Contributions
- 3. Method
- 4. Experiments & Results
- 5. Ablation & Discussion
- 6. Strengths / Limitations / Future Work
- References
1. Summary
Title: vMAP: Vectorised Object Mapping for Neural Field SLAM Authors: X. Kong, S. Liu, M. Taher, A. J. Davison Paper: arXiv:2302.01838 (CVPR 2023) Github: kxhit/vMAP
vMAP (ICL Dyson 机器人实验室, Davison 组, 2023):对象级 (object-level) 神经隐式建图。区别于 iMAP / NICE-SLAM 的统一场表示,vMAP 给每个物体实例(含背景)单独一个小 MLP,从而解耦物体、避免相互干扰,且能按物体独立停/续训、重组新场景。
核心 trick:向量化 (vectorised) 批量并行:把 N 个结构相同的物体 MLP 堆成一个 batch,用 PyTorch functorch (torch.vmap) 一次前向/反传所有物体 → GPU 利用率高,物体数增加几乎不掉速,约 50 个物体仍保 5 Hz 地图更新。
Replica 8 场景:vMAP 物体级 completion 1.44 cm(NICE-SLAM* 3.27 cm / iMAP* 2.38 cm),scene completion ratio 92.99%,建图耗时 8m16s(vs NICE-SLAM 34m34s)。
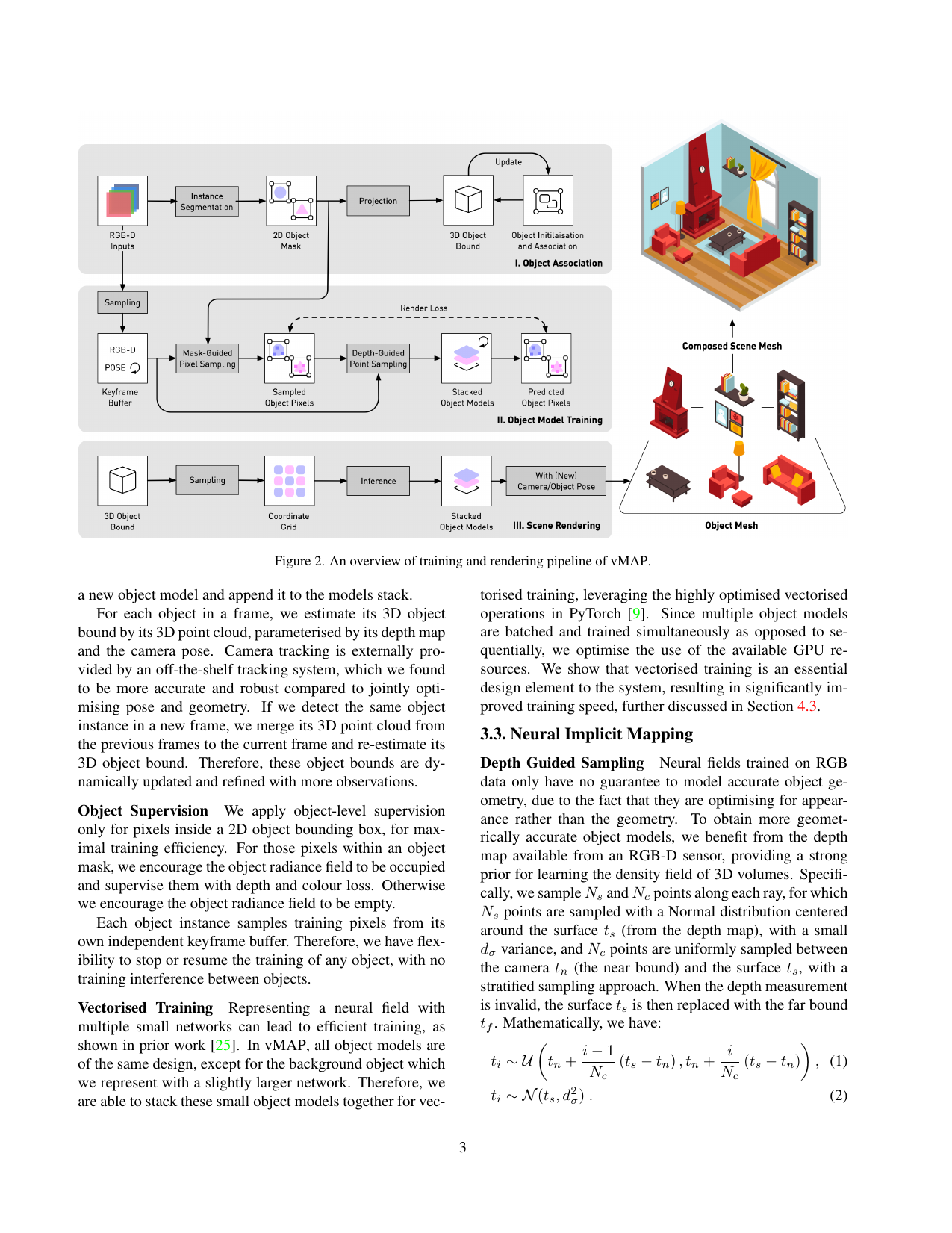
2. Key Contributions
- 对象级表示:每物体一个 MLP (4L×32),背景 MLP (4L×128);解耦、可编辑、水密重建,无需 3D 先验
- 向量化批量训练:同结构 MLP 堆 batch → functorch 批量化前向/反传;实现"对象级仍实时 (5 Hz)"
- 轻量地图:~40 KB/物体,整场景 < 1M 参数(vs NICE-SLAM 12.18M),建图快 4×
- 遮挡感知渲染:Ray-Box 求各物体近远界 → 按深度排序 → 正确遮挡合成
- Detic 开放词表检测:>1000 类在线实例分割,无需预定义类别
3. Method
3.1 对象级 MLP 表示
| MLP | 层数 | 隐藏维 | 参数量 | 用途 |
|---|---|---|---|---|
| 物体 | 4 | 32 | ~40 KB/个 | 各实例局部坐标系 |
| 背景 | 4 | 128 | 较大 | 全局背景,单独训练 |
每个 MLP 在物体局部坐标系内学完整 occupancy 和颜色 → 天然水密 (watertight),遮挡区域仍能补出合理闭合面。每物体维护一个 3D 包围盒,随跨帧观测更新。
3.2 检测与数据关联
- 实例分割:现成检测器 Detic (开放词表 LVIS 预训练,>1000 类) 逐帧出 mask
- 位姿:外部 ORB-SLAM3 提供,不与几何联合优化(外部跟踪更准更鲁棒)
- 数据关联:同时满足两条准则才视为同一物体:
- 语义一致:与前帧预测同一语义类
- 空间一致:两者 3D 包围盒的平均 IoU 超阈值
- 不满足 → 在线动态加入新物体
监督采样在物体 2D 包围盒 内;深度/颜色 loss 仅在 mask 内,occupancy loss 覆盖整个 bbox(mask 外鼓励为空)。
3.3 深度引导采样与渲染
每物体 MLP 独立体渲染,沿光线两路采样:
- 高斯采样 点:以表面深度为中心, cm,聚焦表面附近
- 分层采样 点:在近界到表面之间均匀采,覆盖前景空白区
渲染 occupancy/深度/颜色,占用累积权重 (光线在第 个采样点终止的概率),(透射率,到达采样点 之前未被遮挡的概率)。渲染深度与颜色:
为采样点到相机的深度, 为该点颜色(MLP 输出)。
遮挡合成:Ray-Box Intersection(光线与轴对齐包围盒 AABB 的解析求交,计算光线进出包围盒的 值)求各物体的 → 按渲染深度排序 → 前物体遮后物体,场景级感知合成。
3.4 损失函数
三项 loss:
- :mask 内渲染深度 vs. 观测 L1
- :mask 内渲染颜色 vs. 观测 L1
- :整个 bbox 内的 occupancy 监督;mask 内取观测深度推算二值占用标签(深度附近 = 1,空旷区 = 0),用 BCE(二元交叉熵)对 监督;mask 外区域强制 (无物体)
3.5 向量化批量训练
核心工程:N 个物体 MLP 结构完全相同(隐藏维 32)→ 权重堆成 张量 → PyTorch functorch(函数变换库,提供 torch.vmap 向量化映射,对 batch 维度自动展开前向/反传,避免逐物体循环)批量化,等价于一次优化所有物体 MLP。背景 MLP 尺寸不同,单独训练,不进 batch。
效果:与串行逐物体训练相比,GPU 利用率大幅提升;~50 个物体时每帧建图 226 ms(vs NICE-SLAM 845 ms),仍保 5 Hz 更新。
4. Experiments & Results
数据集
| 数据集 | 说明 | 评估 |
|---|---|---|
| Replica | 8 合成室内场景,RGB-D | 场景/物体级重建质量 |
Replica 建图质量
| Method | Scene Acc (cm) ↓ | Scene Comp (cm) ↓ | Scene Comp Ratio (%) ↑ | Obj Comp (cm) ↓ | Obj Comp Ratio (<1cm, %) ↑ |
|---|---|---|---|---|---|
| TSDF-Fusion | 1.28 | 5.61 | 82.67 | 3.69 | 61.70 |
| iMAP* | 2.15 | 2.88 | 90.85 | 2.38 | 47.79 |
| NICE-SLAM* | 3.04 | 3.84 | 86.52 | 3.27 | 37.79 |
| vMAP | 3.20 | 2.39 | 92.99 | 1.44 | 69.23 |
- Scene Accuracy (大面片 — 墙/地) 上 TSDF-Fusion、iMAP* 优于 vMAP(场景级 Acc 偏大物体)
- 物体级指标(comp/comp_ratio)vMAP 领先明显;Scene Completion Ratio 最高 (92.99%)
- 建图耗时:vMAP 8m16s vs. NICE-SLAM 34m34s(快约 4×);每帧 226 ms vs. 845 ms
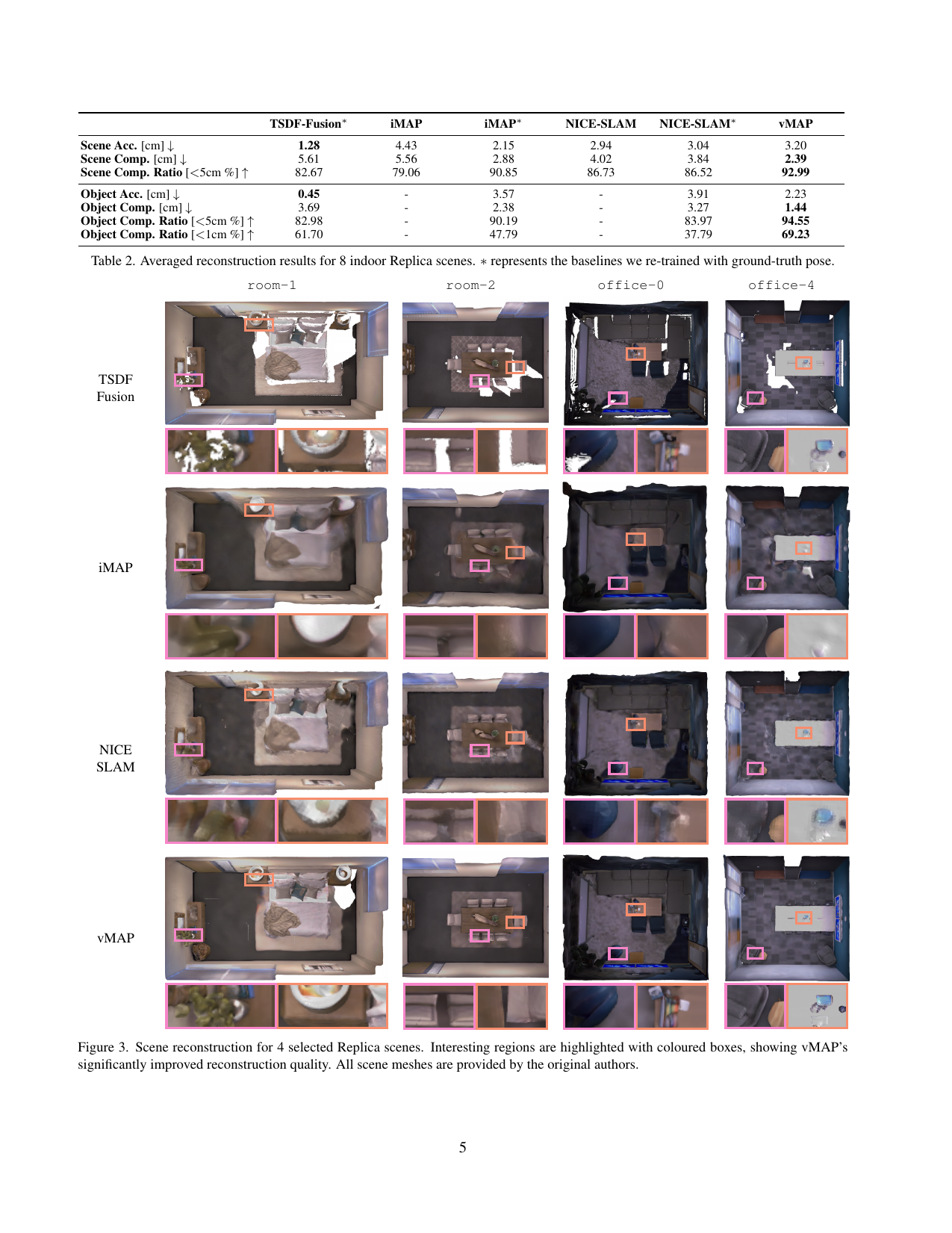
5. Ablation & Discussion
论文消融主要针对 MLP 尺寸、采样策略和向量化效率:
- 向量化 vs 串行:串行逐物体训练在物体数增多时速度急剧下降;向量化几乎线性保持,50 个物体仍 5 Hz
- 物体 MLP 隐藏维 32 vs 64/128:32 维在速度/质量间最优(更大收益边际递减,且不能再向量化)
- Depth-guided vs 均匀采样:高斯 + 分层采样显著优于纯均匀采样,尤其物体细节
数据关联质量依赖 Detic mask 的时空一致性;Detic 误检 → 物体分裂或合并。
6. Strengths / Limitations / Future Work
Strengths
- 对象级解耦:可独立编辑/迁移/重组物体
- 向量化实现真正实时 (~5 Hz),速度比 NICE-SLAM 快 4×
- 物体级重建质量领先(comp 1.44 cm vs NICE-SLAM* 3.27 cm)
Limitations
- 依赖外部实例分割 (Detic) 的时空一致性;误检导致数据关联失败
- 完全在视野外的区域(如整面未见的椅背)无 3D 先验,仍无法补全
- 位姿由外部 ORB-SLAM3 提供,与几何未联合优化
Future Work
- 位姿与对象 MLP 联合优化
- 动态物体处理
- 场景可组合性在机器人操作中的应用
References
- Kong, X., Liu, S., Taher, M., & Davison, A. J. (2023). vMAP: Vectorised Object Mapping for Neural Field SLAM. CVPR 2023. arXiv:2302.01838
- 项目页: kxhit.github.io/vMAP
- 代码: github.com/kxhit/vMAP
- iMAP 笔记:前作单 MLP 场景表示
- NICE-SLAM 笔记:分层网格对照